Paper Reading List¶
Step0: Basic Concepts¶
如果之前对 DL 的基本概念不是很熟悉,可以先看一些基础的 DL 论文。 如一些介绍性的论文,见Deep Learning Papers。 此外,DL 的一个核心是 BP 算法,相关的论文可以参考Backpropagation。
Step1: NMT, Attention and Transformer¶
Reference Blogs
TODO: 2014-Google-Sequence to Sequence¶
Sequence to Sequence Learning with Neural Networks
2014-Bengio-Attention¶
Neural Machine Translation by Jointly Learning to Align and Translate1. 本文首次提出了 Attention 的概念,首先介绍了什么是 Neural machine translation(NMT): attempts to build and train a single, large neural network that reads a sentence and outputs a correct translation.
之后指出当时现有的 NMT model 大多属于 encoder-decoder 类型的网络: An encoder neural network reads and encodes a source sentence into a fixed-length vector. A decoder then outputs a translation from the encoded vector. 在这种框架下,A neural network needs to be able to compress all necessary information of a source sentence into a fixed-length vector. 那么就有一个潜在的问题,在 source sentence 过长的时候, 这里得到的 fixed-length vector 不足以表达全部的信息, 所以后面基于此 vector 的翻译任务将很难有好的表现, 如下图1所示:
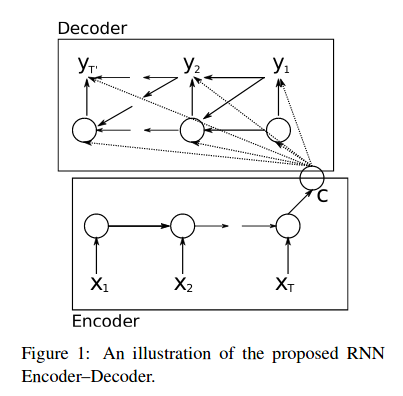
在T较大的时候,C很难将全部的信息综合起来,损失了较多的信息,所以使得 Decoder 很难有好的表现。
接着就是文章提出方法的具体描述了: The most important distinguishing feature of this approach from the basic encoder–decoder is that it does not attempt to encode a whole input sentence into a single fixed-length vector. Instead, it en-codes the input sentence into a sequence of vectors and chooses a subset of these vectors adaptively while decoding the translation. This frees a neural translation model from having to squash all the information of a source sentence, regardless of its length, into a fixed-length vector.
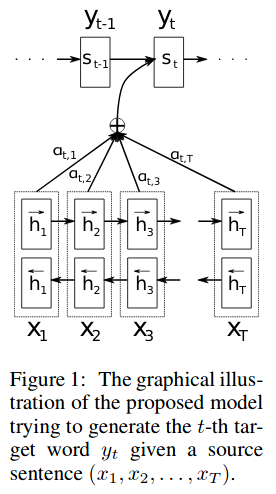
上图 (来自本文) 进一步地补充了上面的解释。这里的 Encoder 是一个双向 RNN, Decode 仍然是一个 RNN。 不同的是,我们不再将 source sentence 的全部信息强行压缩到一个 fixed-length vector, 而是加上了一个 alignment model,其在每次预测\(y_t\)的时候都会汇总来自 Encoder 隐藏层的信息 (annotations, 双向 RNN 拼接而成) 作为输入。
接下来解释了为什么这样方法是有效的:Intuitively,this implements a mechanism of attention in the decoder. The decoder decides parts of the source sentence to pay attention to. By letting the decoder have an attention mechanism, we relieve the encoder from the burden of having to encode all information in the source sentence into a fixed-length vector. With this new approach the information can be spread throughout the sequence of annotations, which can be selectively retrieved by the decoder accordingly.
关于 alignment model 的实现:We parametrize the alignment model as a feedforward neural network which is jointly trained with all the other components of the proposed system.
综上可知,这里的 Attention 就是说在预测的时候持续“关注”source sentence(输入) 以获得更好的预测, 而完成这个“关注”任务的,协调“关注”工作的任务就交给了 Attention Mechanism 的实现,如这里的 alignment model.
PyTorch Practice
算法的PyTorch实现: pcyin/pytorch_basic_nmt
PyTorch教程: NLP From Scratch: Translation with a Sequence to Sequence Network and Attention
TODO: 2017-Transformers¶
Attention Is All You Need
Step2: GPT Series¶
2018-OpenAI-GPT1.0¶
Improving Language Understanding by Generative Pre-Training
2018-Google-BERT¶
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
2019-OpenAI-GPT2.0¶
Language Models are Unsupervised Multitask Learners
2020-OpenAI-GPT3.0¶
Language models are few-shot learners
Step3: Engineering in LLM¶
TBD