P value or Effect size
起因是看到业务显著性与统计显著性这篇文章,发现看完之后除了加深了下统计显著容易让人陷入认知误区的印象之外,更多的是一堆问号。文中提及的 Effect size 和 Probability of Superiority 这些概念之前没有了解过,当我想通过具体的例子了解一下时,我发现例子比概念本身更加难以理解...
Example
以下面的虚拟实验为例。我们想研究做作业对学习效率的影响。这个实验对 150 个学生进行了 AB 随机分组,75 个学生要求做作业,而另外 75 个学生不做作业, 在一个月后用一个包含 20 道题的标准化考试来衡量效果,预期得分提升一个点。最后的结果是不做作业的那一组平均得分 15.6 分,而做作业的组, 平均得分 17.3,提高了 1.7 分。统计检验在 97.5% 的显著性要求下通过。如果分析就到此为止也没有什么问题,但是优秀的分析师会对平均提高 1.7 分进行进一步的解读。 比如,在这个实验中,结合样本的均方差,组间差异平均提高 1.7 分意味着两组有 88% 的重合,或者说实验组随机挑选一个学生, 这个学生有 58.4% 的概率比对照组随机挑选的一个学生的得分要高(称之为 probability of superiority)。 此外,如果想要在实验组中获得比对照组多一个学生的成绩更好,我们平均需要让 10.6 个学生做作业,换句话说,如果有 100 个学生都严格执行了做作业的学习过程, 相比他们不做作业的学习过程,平均来说有 9.4 个学生会得到更好的考试结果。这样的解读会让主管或者业务方更好地理解实验的应用意义。”
个人而言,相比从例子本身去理解什么,先理解这个实验本身或者说理解这个实验的详细流程更为重要。 换句话说,这个实验是描述了实验本身 (也没有很详细),同时给出了大致的分析方向。但是,很显然具体实验的过程才是更加重要的。 这种分析方式有无限制或者前提假设?88%,58.4%,10.6, 9.4如何计算出来的?抛弃这些真正实用的操作过程和理论支撑,那么这个例子对实践的指导意义又能有多少呢? 如果说是为了尽可能摆脱繁杂的背景知识来提供某种 insight, 那后面扯上“并行”,“异步”又是为哪般呢...
另外,本文论述大多参考Interpreting Cohen's d Effect Size: An Interactive Visualization, 如果这篇文章可以解答疑惑,下面的论述也就没有必要了。
Definitions¶
Effect size¶
首先看下 Wikipedia 对 Effect size 的定义:
Note
In statistics, an effect size is a number measuring the strength of the relationship between two variables in a statistical population, or a sample-based estimate of that quantity...Examples of effect sizes include ... mean difference.
论文Using Effect Size—or Why the P Value Is Not Enough也给出了 Effect size 的定义:
Note
In medical education research studies that compare different educational interventions, effect size is the magnitude of the difference between groups.
简言之,Effect size 可以用来衡量不同 group 之间的差异性。同是论文给出了 Effect size 的两种形式:
Note
Thus, effect size can refer to the raw difference between group means, or absolute effect size, as well as standardized measures of effect, which are calculated to transform the effect to an easily understood scale.
也就是 Effect size 存在两种形式,一种是在原有量纲下直接做差得到的结果,一种是标准化之后的结果。我们下面将要论述的 Cohen's d 就是属于后者。另外值得一提的是,Logistic Regression 中经常提到的 Odds ratio 也属于 Effect size Indices 的一种。
Cohen's d¶
参考Wikiversity中对 Cohen's d 的定义:
Note
Cohen's d is an effect size used to indicate the standardised difference between two means.
上述定义固然清晰简洁,但是不够具体,Wikipedia给出了具体的计算方式: $$ d = \frac{\bar{x}_1 - \bar{x}_2}{s} $$
此外,在 Cohen, J. (1977). Statistical power analysis for the behavioral sciencies. Routledge.章节 2.2 THE EFFECT SIZE INDEX: d 中给出了具体的计算例子。
How¶
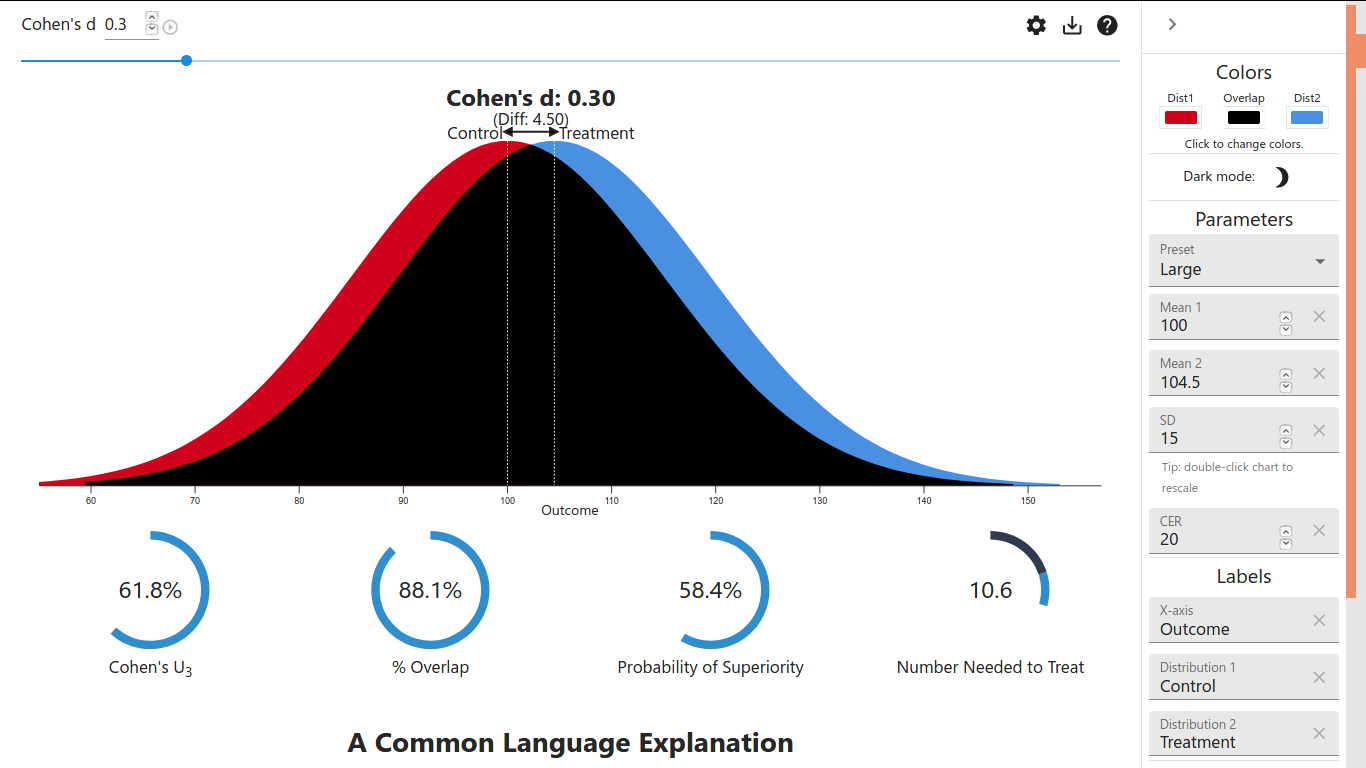
下面我们先不加解释地给出如何计算得到上面所说的那几个数字。因为原文对实验的描述并不全面,也就是不知道两组学生分数的标准差,所以我们很难模拟出来原始的例子...但是因为所有的计算几乎全部依赖于Cohen's d,所以通过尝试不同的值 (:-), 发现只要让Cohen's d=0.3就可以得到相同的结果。
也就是说,当我们有真实的数据时,我们可以根据 Definition 中对 Cohen's d 的定义计算出对应的值,记为\(\delta\),之后的分析和各种数据指标的计算全部是基于这个值的。因为现在我们没有数据,所以只能以这个倒推出来的值\(\delta=0.3\)为起点展开后续的计算。
下面我将不加过多阐述地给出各个指标的计算流程,具体分析与推导见后续 What。
Overlap: overlapping coefficient (OVL): $$ OVL = 2 \Phi(-|\delta|/2) = 2\Phi(-0.15) = 2 \times 0.4403823 = 0.8807646 \approx 88\% $$ 也就是上面例子中重叠占比 88% 的由来。注意这里\(\Phi\)为标准正态分布的累积密度函数 (CDF), 这里的\(\Phi(-0.15)\)在 R 语言用pnorm(-0.15)即可算得.
Probability of superiority: common language effect size (CL): $$ CL = \Phi(\frac{\delta}{\sqrt2}) = \Phi(0.3/\sqrt2) = 0.583998 \approx 58.4\% $$ 也就是上面例子中 58.4% 的由来。
Number Needed to Treat(NNT): $$ NNT = \frac{1}{\Phi(\delta + \Psi(CER))- CER} = \frac{1}{\Phi(0.3 + \Psi(0.2))- 0.2} = 10.6338 $$ 关于这里的 CER 参考附录 CER&EER&NNT. 这里\(\Psi\)函数为\(\Phi\)的反函数,在 R 中为qnorm. 上述计算就是 10.6 的由来。也就是说,那个例子的计算中是默认了 CER 为 0.2 的...
TODO: 至于例子中这个 9.4, 我直观感觉应该是\(100 \times \frac{1}{10.6}=9.433962\),但是有点绕不过来 Orz
Cohen's \(U_3\): $$ U_3 = \Phi(\delta) = \Phi(0.3) = 0.6179114 \approx 61.8\% $$
在 Cohen, J. (1977). Statistical power analysis for the behavioral sciencies. Routledge.中,定义了\(U_1, U_2, U_3\),分别用来衡量不重叠性 ("measures of nonoverlap").这里的例子没有涉及,但也是很有用的概念。
What¶
在写这块的时候发现自己很难把问题讲清楚,所以就拜托 Tomorrow 学长写了这一部分Two-Sample Test and Cohen's d, 文中给出了上述公式的详细推导。另外舍友也讨论了这个问题,他也从另一个角度定义并计算了上述问题,并检查了以上论述。感谢两位:-)
And...¶
Where is the P value?¶
本文题目是P value of Effect size, 然而并未对 P value 作出更多的论述,主要是因为论文Using Effect Size—or Why the P Value Is Not Enough已经对两者作出了相当充分的讨论,无需赘述。此外关于 P value 的争论 (P value culture) 已经存在很久了,但是学校好像几乎没怎么提及...如Ranstam, Jonas. "Why the P-value culture is bad and confidence intervals a better alternative."。P value 本身并没有问题:“我就是个小小的 P value, 我能有什么坏心思呢?”错的是我们不能正确地认识它。
Probability of superiority¶
之前写过一篇ROC-AUC详细介绍了 ROC 和 AUC 相关的东西:WHEN, WHERE, WHO, WHY, HOW. 主要是点出来 AUC 与非参数统计中 Wilcoxon-Mann-Whitney statistic 的关联。而这里的所说的 Probability of superiority 其实就是 AUC,核心就是对“配对比较”的理解,“配对”无非就是做一个笛卡尔积。
Tip
另外一提,在ROC-AUC这篇文章中介绍的计算AUC的最快的方法,是WXG 的算法岗面试题
何为直观?¶
文章最开始给出的那段话,无非是为了让人了解到所谓进一步做分析的必要性。 但是仅仅给出一堆莫名奇妙的数字,而且不给原理,不给出处,不能实验,又何谈应用到业务中去呢。 即使在被各种"直观","可视化"解释包围的今天,我们也不能忘记那些看似抽象的定义才是根本...
附录:CER&EER&NNT¶
参考bandolier:
Event rate: The proportion of patients in a group in whom the event is observed. Thus, if out of 100 patients, the event is observed in 27, the event rate is 0.27 or 27%. Control event rate (CER) and experimental event rate (EER) are used to refer to this in control and experimental groups of patients respectively. An example might help.
Example
| Treatment | 总人数 | 疼痛减少50%以上的人数 | 疼痛没有减少50%以上的人 |
|---|---|---|---|
| 布洛芬400 mg | 40 | 22 | 18 |
| 安慰剂 | 40 | 7 | 33 |
Experimental event rate (EER, event rate with ibuprofen): 22/40 = 0.55 or 55%
Control event rate(CER, event rate with placebo): 7/40 = 0.18 or 18%
Absolute risk increase or reduction (EER-CER): 0.55 - 0.18 = 0.37 or 37%
NNT (1/(EER-CER)):1/(0.55 - 0.18) = 2.7
显然,这里的 Event 也就是我们关注的地方是“疼痛减少 50% 以上”