classDawidSkene(BaseClassificationAggregator):# 省略部分代码@staticmethoddef_m_step(data:pd.DataFrame,probas:pd.DataFrame,initial_error:Optional[pd.DataFrame]=None,initial_error_strategy:Optional[Literal["assign","addition"]]=None,)->pd.DataFrame:"""Performs M-step of the Dawid-Skene algorithm. Estimates the workers' error probability matrix using the specified workers' responses and the true task label probabilities. """joined=data.join(probas,on="task")joined.drop(columns=["task"],inplace=True)errors=joined.groupby(["worker","label"],sort=False).sum()# Apply the initial error matrixerrors=initial_error_apply(errors,initial_error,initial_error_strategy)# Normalize the error matrixerrors.clip(lower=_EPS,inplace=True)errors/=errors.groupby("worker",sort=False).sum()returnerrors
definitial_error_apply(errors:pd.DataFrame,initial_error:Optional[pd.DataFrame],initial_error_strategy:Optional[Literal["assign","addition"]],)->pd.DataFrame:ifinitial_error_strategyisNoneorinitial_errorisNone:returnerrors# check the index names of initial_errorifinitial_error.index.names!=errors.index.names:# (1)raiseValueError(f"The index of initial_error must be: {errors.index.names},"f"but got: {initial_error.index.names}")ifinitial_error_strategy=="assign":# check the completeness of initial_error: all the workers in data should be in initial_errormask=errors.index.isin(initial_error.index)ifnotmask.all():# (2)not_found_workers=errors.index[~mask].get_level_values("worker").unique()raiseValueError(f"All the workers in data should be in initial_error: "f"Can not find {len(not_found_workers)} workers' error matrix in initial_error")# if the values in initial_error are probability, check the sum of each worker's error matrixif(initial_error<=1.0).all().all()andnotnp.allclose(initial_error.groupby("worker",sort=False).sum(),1.0):# (3)raiseValueError("The sum of each worker's error matrix in initial_error should be 1.0")errors=initial_errorelifinitial_error_strategy=="addition":# (4)errors=errors.add(initial_error,axis="index",fill_value=0.0)else:raiseValueError(f"Invalid initial_error_strategy: {initial_error_strategy},"f"should be 'assign' or 'addition'")returnerrors
赋值策略下,是允许混淆矩阵是 count 或者 probability 的。如果检查到传入的混淆矩阵是 probability,需要保证混淆矩阵的合法性。
加法策略下,是将传入的混淆矩阵加到原有的混淆矩阵上。注意,这里需要保证传入的混淆矩阵的值为 count 而不是 probability (这点在文档 做了特别说明)。
S. Borman, “The expectation maximization algorithm-a short tutorial,” Submitted for publication, vol. 41, 2004. ↩
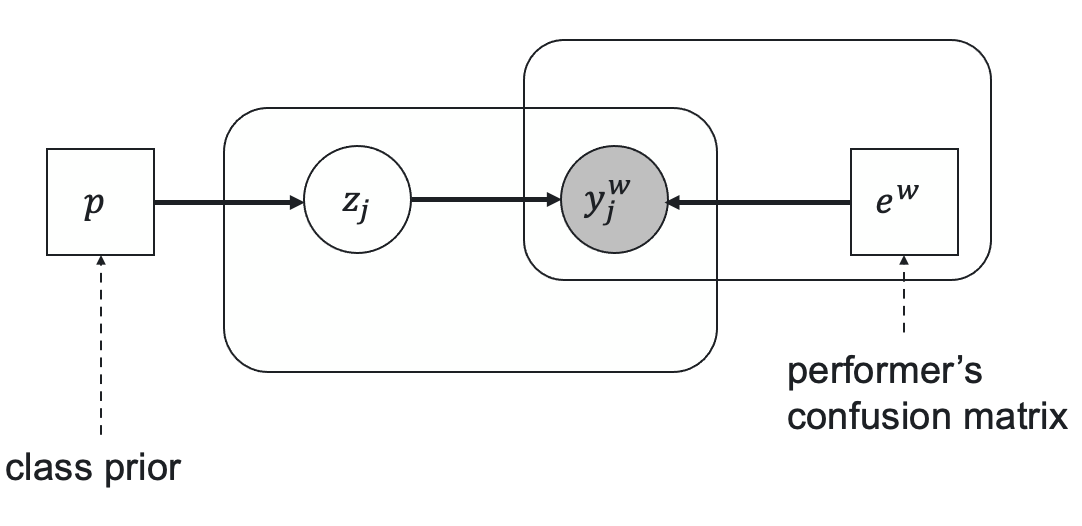
A. P. Dawid and A. M. Skene, “Maximum likelihood estimation of observer error-rates using the EM algorithm,” Journal of the Royal Statistical Society: Series C (Applied Statistics), vol. 28, no. 1, pp. 20–28, 1979. ↩