ROC-AUC
Note
"You are writing a book because you are not entirely satisfied with the available texts." -- George Casella
When&Where&Who&Why¶
任何事物,包括一个概念,理论的提出必然有其历史背景,有其原因,也就是所谓的Motivation. 所以要想真正认识ROC和AUC必须追溯其历史,这要从1941年日军偷袭珍珠港说起...
Tip
The ROC curve was first used during World War II for the analysis of radar signals before it was employed in signal detection theory. [44] Following the attack on Pearl Harbor in 1941, the United States army began new research to increase the prediction of correctly detected Japanese aircraft from their radar signals. For these purposes they measured the ability of a radar receiver operator to make these important distinctions, which was called the Receiver Operating Characteristic. --Wikipedia
也就是说,在珍珠港战役之后,美军迫切地需要侦测技术的提升来更好地检测到日军飞机的入侵,所谓提升必然要有比较的指标,这个指标就是ROC.
在《百面机器学习》的第二章提到了ROC曲线具体的由来。
Note
ROC曲线最早是运用在军事上的,后来逐渐运用到医学领域,并于20世纪80年代后期被引入机器学习领域。相传在第二次 世界大战期间,雷达兵的任务之一就是死死地盯住雷达显示器,观察是否有敌机来袭。理论上讲,只要有敌机来袭,雷达屏幕上 就会出现相应的信号。但是实际上,如果飞鸟出现在雷达扫描区域时,雷达屏幕上有时也会出现信号。这种情况令雷达兵烦恼不 已,如果过于谨慎,凡是有信号就确定为敌机来袭,显然会增加误报风险;如果过于大胆,凡是信号都认为是飞鸟,又会增加漏报的风险。每个雷达兵都竭尽所能地研究飞鸟信号和飞机信号之间的区别,以便增加预报的准确性。但问题在于,每个雷达兵都 有自己的判别标准,有的雷达兵比较谨慎,容易出现误报;有的雷达兵则比较胆大,容易出现漏报。
为了研究每个雷达兵预报的准确性,雷达兵的管理者汇总了所有雷达兵的预报特点,特别是他们漏报和误报的概率,并将 这些概率画到一个二维坐标系里。这个二维坐标的纵坐标为敏感性(真阳性率),即在所有敌机来袭的事件中,每个雷达兵准确 预报的概率。而横坐标则为1-特异性(假阳性率),表示在所有非敌机来袭信号中,雷达兵预报错误的概率。由于每个雷达兵的 预报标准不同,且得到的敏感性和特异性的组合也不同。将这些雷达兵的预报性能进行汇总后,雷达兵管理员发现他们刚好在一条曲线上,这条曲线就是后来被广泛应用在医疗和机器学习领域的ROC曲线。
现在我们可以来尝试回答为什么会有ROC曲线的存在了,就是我们需要一种更加稳健的衡量指标来判断某样东西的好坏,在探索这个指标的过程诞生了ROC曲线.在后面的分析中,我们可以更加直观地搞明白其为什么是稳健的。
我这里用“某样东西”是因为其不仅仅包含大家熟知的二分类器和上面的雷达探测仪器,它包含更多的东西。
What¶
说了那么久,那么到底ROC是什么东西呢?简单地讲,是个曲线图。
Note
A receiver operating characteristic curve, or ROC curve, is a graphical plot that illustrates the diagnostic ability of a binary classifier system as its discrimination threshold is varied. --Wikipedia
Wiki上明确地给出我前面说的“某样东西”是一个"binary classifier sysytem", 即一个二分类系统(再次强调,请不要局限在ML里面的二分类...一个分辨灯泡好坏的仪器同样是一个二分类系统,这在质量管理中的例子很多).
那么,现在我们知道了ROC曲线是一个图,它衡量一个二分类系统的诊断能力,同时其每一个点是根据一个threshold得到,我们变换这个threshold就得到了一系列的点,连点成线就得到了ROC曲线。
那么现在就剩下一个问题,即如何根据这个threshold来获取ROC曲线上的点。这里需要引入一些定义。
Note
正类: Positive class,正品,阳性, 用1表示
负类: Negative class,次品,阴性,用0表示
TP, FP, TN, FN: True Positive, False Positive, True Negative, False Negative
TPR: True Postive Rate, Recall, Sensitivity, \(\(TPR = \frac{TP}{TP+FN}\)\)
FPR: False Positive Rate, Fall-out, \(FPR=\frac{FP}{FP+TN}\)
预测值: Score,二分类系统给样本的打分,实数范围R
阈值: Threshold
ROC定义横轴为FPR,纵轴为TPR。进而问题转化成如何从Threshold \(T\)得到对应点的横纵座标,即\((FPR_T, TPR_T)\).从某个集合\(S_T\)中取不同的阈值\(T\),就得到一系列的横纵座标,也就是ROC曲线上的一系列点\(\{(FPR_T, TPR_T) | T \in S_T\}\), 也就得到了ROC曲线。
一般来说,二分类系统的直接结果是一个连续的值即Score,而不是0或1的Class,或者说,从更广义的角度来说,这是一个合理的假定。而\(TP, FP, FN, TN\)等的计算是是直接依赖类别的,而Threshold就是一个沟通预测Score与Class的桥梁。我们通常约定Score大于Threshold则预测为1,否则预测为0
虽然说的很麻烦,但是整个流程很简单: 拟定\(T\)的取值集合\(S_T\), 将测试样本进入二分类系统,得出Score(将Score按升序排列),根据每个\(T\)进而计算\(TP, FP, FN, TN\), 最后有 \(\{(FPR_T, TPR_T) | T \in S_T\}\), 连点成线即可。
因为Score的取值范围为\(R\), 所以\(T\)的取值理论上也是\(R\), 但是在此问题中,我们可以将其缩小到\([min(Score), max(Score)]\)(这里的Score是指根据样本计算出的实际的数列), 想一想为什么(hint: 考虑\(TP, FP, FN, TN\)的计算), 一般均匀地取上几十个点就足够了,当然这也要看具体的样本量。这里其实又衍生出另外一个问题,而这个问题又给出了另外一种在实际中绘制ROC曲线的方法,当然本质上还是上面说的那种,只是实践起来略有差别。
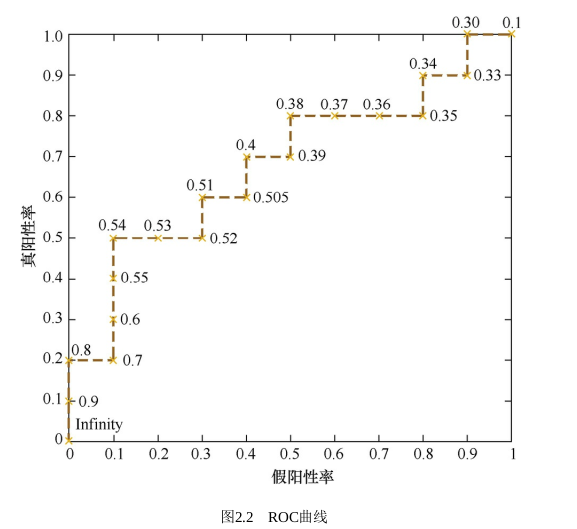
在样本很多的时候,我们可以取一些阈值,好比是10个,然后得到10个点,绘制出ROC曲线;如果我们取20个阈值,显然绘制出的ROC曲线会更加“精细”一些。那么这就是我前面说到的衍生的问题了,我们可以绘制出无限精细的ROC曲线吗?如果不能,我们能够做到的“精细”的极限又在哪里呢?答案是不能无限精细,其精细的极限由样本量控制。那么,为什么呢?看下面这种绘制ROC曲线的方法,你就明白了。
Tip
首先,根据样本标签统计出正负样本的数量,假设正样本数量为P,负样本数量为N;接下来,把横轴的刻度间隔设置为1/N,纵轴的刻度间隔设置为1/P;再根据模型输出的预测概率对样本进行排序(从高到低);依次遍历样本,同时从零点开始绘制ROC曲线,每遇到一个正样本就沿纵轴方向绘制一个刻度间隔的曲线,每遇到一个负样本就沿横轴方向绘制一个刻度间隔的曲线,直到遍历完所有样本,曲线最终停在(1,1)这个点,整个ROC曲线绘制完成。 --《百面机器学习》
How¶
在搞清楚ROC是什么之后,我们需要知道它到底怎么来衡量二分类系统的好坏呢?或者说什么样的曲线是说明系统分类的性能比较好?这首先要研究下ROC曲线的一些性质。
首先,其必过(0, 0)与(1, 1)两点: \(\forall T \in (-\inf, min(Score))\), 样本全部被预测为1, \(FPR=1, TPR=1\), 即过点(1, 1); \(\forall T \in (max(Score), \inf)\),样本全部被预测为0, \(FPR=0, TPR=0\), 即过点(0, 0).
所以上面说的\(T\)的取值范围可以限制在\([min(Score), max(Score)]\)的原因就一目了然了~
其次是我们希望二分类系统的FPR尽可能小的同时TPR尽可能地大,对应到ROC曲线就是曲线尽可能向左上方靠近。一个很好的辅助线就是\(y=x\),即连接上述两点的对角线。在ROC Space(详见Wikipedia)中,这条曲线表示二分类系统中衡有FPR=TPR,也就说这种分类系统就是随机给出的预测,毫无任何意义。我们的ROC 曲线一般都是在其上方的。
这里其实还可以问一下,ROC总是在\(y=x\)的上方吗?我觉着这个问题值得停下来取想一下的。这个问题的答案当然是否定的。因为我们一般遇到的结果效果都比较好,所以不存在这种情况,但是确实是存在这种情况的。举一个极端的例子,设计好一个二分类系统后,我们给定的测试样本全是负样本,那么无论如何得到的ROC曲线一定是X轴上的一条直线,必然是在\(y=x\)下面的!
然后呢,还有一个问题就是我们仅仅知道偏左上方比较好是不够的,定性的方法还是不如定量的方法来的实用。在两个系统的ROC曲线都是偏左上方,并且看起来没什么大的差别时如果比较呢?答案就是AUC(Area under the curve)了,即ROC曲线下的面积(这里没有具体去查AUC引入的历史,不过其引入也算是比较自然的,究其本质,面积即积分,积分即累加)。
先说结论,一般认为AUC大的分类系统更好一些。而且AUC除了定量地表示了偏左上的程度之外还有一个很好的性质,就是其取值范围在0和1之间,可以很方便地进行比较。考虑上面的\(y=x\)时为随机猜正负,其AUC为0.5, 所以我们的分类系统AUC的底线就是0.5,越高越好。
AUC¶
对AUC的解释有很多,其中有个被问烂的问题就是其所谓的“物理意义”...(真就“为什么JAVA实现中链表长度到8就变红黑树”呗:-)
AUC的概率解释在Wikipedia中有详细的推导.
其中\(X_1\)是正类的的\(Score\), \(X_2\)是负类的\(Score\). 此外AUC也是Wilcoxon-Mann-Whitney statistic,公式如下,这里的\(f\)指二分类系统. $$ A U C(f)=\frac{\sum_{t_{0} \in \mathcal{D}^{0}} \sum_{t_{1} \in \mathcal{D}^{1}} \mathbf{1}\left[f\left(t_{0}\right)<f\left(t_{1}\right)\right]}{\left|\mathcal{D}^{0}\right| \cdot\left|\mathcal{D}^{1}\right|} $$ 总而言之就是
When using normalized units, the area under the curve (often referred to as simply the AUC) is equal to the probability that a classifier will rank a randomly chosen positive instance higher than a randomly chosen negative one (assuming 'positive' ranks higher than 'negative')
也就是说AUC本质上是一个平均值,对正负样本集做笛卡尔积,然后每对样本中比较正类与负类的\(Score\)大小,找出那些正类得分大于负类得分的配对,其数量与总的配对数量之比就是AUC的值。
那么,根据上面的计算公式,我们能够理解AUC的稳健之处正是在于其平均了每种配对的情况,这也是在样本类别不均衡时用AUC来衡量模型的原因。
其实还有一个很有趣的问题,就是AUC的代码实现,这个我是没有去查过目前已有的实现的,但是通过上面的解释,我们大概有两种方法去计算,第一就是用Wilcoxon-Mann-Whitney statistic,基于计数去算;第二个是从给出的精细ROC绘制方法入手。那么问题来了,那个更快呢?
末¶
想知道ROC怎么from scratch来用代码画吗?想了解AUC两种计算方式的benchmarking吗?想...也没有续集了,或许要等下年五一了:-)